|
||||
|
ТЕХНОЛОГИИ: Зрение роботов Автор: Алексей Калиниченко Мы живем в трехмерном мире, а смотрим на него лишь двумя глазами. Наши глаза передают в мозг две картинки, из которых он формирует представление об окружающем пространстве. Роботам, обычно получающим визуальную информацию при помощи видеокамер, тоже нужно знать о трехмерной структуре мира. Но если мозг может легко понять, какие объекты на картинках, полученных от каждого из глаз, соответствуют друг другу, то компьютеру справиться с этой задачей не так просто[Эта задача называется сегментацией]. Давайте рассмотрим, как люди воспринимают трехмерный мир. Для этого мы используем как минимум три инструмента. Прежде всего, конечно, бинокулярное зрение. Поскольку наши глаза отстоят друг от друга на некоторое расстояние, то анализируя картинки, полученные с их помощью, мозг может судить о том, какие предметы находятся дальше от нас, а какие ближе. В самом деле, если мы знаем расстояние между двумя точками (глазами) и углы, под которыми видим третью, то при помощи несложных тригонометрических формул мы можем найти и расстояние от третьей точки до любого из глаз. Следующий инструмент основан на, казалось бы, недостатке человеческого глаза — он имеет конечную глубину резкости[Расстояние между ближней и дальней границами пространства, в пределах которого объекты находятся в фокусе (на снимке получаются достаточно резко)], то есть мы не можем видеть с хорошей резкостью сразу оба предмета, если первый находится от нас на расстоянии один метр, а второй удален на десять метров. Соответственно если изображения двух предметов будут резкими, то можно сделать вывод, что они находятся на приблизительно одинаковом расстоянии от нас. И третий, уже скорее психологический, инструмент использует тот факт, что мы обычно имеем дело с хорошо знакомыми нам предметами — например, все примерно представляют, какого размера должна быть табуретка или кровать. Поэтому для определения расстояния до таких предметов мозгу достаточно знать, какая площадь на сетчатке занята их изображением. Естественно, что все эти методы работают в комплексе, взаимно дополняя и уточняя друг друга. Также огромную роль играет способность человека выделять объекты из того потока информации, которую он получает благодаря органам зрения. Грубо говоря, когда мы входим в незнакомую комнату, нас не интересует форма стоящего в углу кресла, нам нужно лишь знать, с какой стороны и как далеко от нас оно находится. А вот роботу, как уже было сказано, даже идентифицировать кресло на изображении комнаты не всегда под силу. Какими же из этих методов могут воспользоваться роботы? Проще всего реализовать второй способ. В самом деле, роботу достаточно иметь один-единственный глаз, и при этом чем меньше у него глубина резкости, тем лучше. Надо «прогнать» камеру по всему диапазону фокусных расстояний и на полученной картинке определить дальность до каждой точки. Но за простотой этого метода скрывается и его недостаток — низкое разрешение. Определить степень сфокусированности можно только для относительно большого по площади предмета; более того, он еще должен быть неравномерно окрашен. Роботу трудно ориентироваться в пустой комнате с чистыми белыми стенами, зато расстояние до какой-нибудь решетки он вычислит точно. Теперь рассмотрим двуглазого робота, который для определения расстояния до предметов использует бинокулярное зрение. Тут возможны два случая: или заранее известно взаимное расположение камер (они закреплены жестко), или потребуется определять положение камер. С первым случаем, казалось бы, все просто: берем точку на одном кадре, ищем соответствующую ей на другом и определяем расстояние до камер. Но все как раз и упирается в поиск соответствий между точками. Для некоторых областей изображения таких соответствий может не оказаться — например, одна из пары соответствующих точек будет чем-то загорожена. Но даже если все соответствия имеются, то найти их будет очень не просто. Рассмотрим простейший случай: наш двуглазый робот смотрит на кубик с гладкими однотонными стенками, и как бы мы ни старались и не разглядывали изображения, полученные с каждого из глаз, найти соответствующих пар точек больше, чем углов у кубика, невозможно. А даже по восьми точкам (предположим, что видны все углы) пытаться восстановить сцену, не зная, что на ней куб, задача нереальная. Большинство оптических методов разрабатываются в расчете на центрально проецирующие камеры. Напомню, что при такой проекции прямые остаются прямыми, а если мы посмотрим на снимки, сделанные реальными фотоаппаратами, то увидим, что зачастую прямые линии выгибаются от центра кадра (особенно по краям). Эти недостатки свойственны камерам с небольшим объективом, а именно такие и устанавливаются на большинство роботов. Естественно, если искажения на кадре будут столь заметны, то восстановить по ним 3D с хорошей точностью не удастся. Чтобы можно было бороться с этой проблемой, применяется процедура калибровки камеры. Если в модели центральной проекции камера имеет всего один параметр (фокусное расстояние), то в реальности к нему добавляется несколько параметров (их число зависит от выбранной модели), описывающих свойства «бочки». Далее фотографируют что-то с заранее известной структурой (это может быть шахматная доска, или решетка, или лист бумаги с нанесенными в определенных местах точками) и по полученному кадру определяют параметры камеры. Теперь любой кадр, сделанный ею, можно с достаточно хорошей точностью привести к виду, соответствующему центральной проекции. И уже преобразованный таким образом кадр использовать для алгоритмов восстановления 3D. Какие есть пути решения данной проблемы? Можно искать на изображениях соответствия не только точек, но и прямых и эллипсов (проекция окружности). Ведь роботы скорее всего будут находиться в антропогенной среде, а современные офисные интерьеры и городские пейзажи практически полностью состоят из прямых линий, да и окружности встречаются нередко. Вернемся к примеру с кубом. Пусть нам удалось найти соответствия между углами, тогда отыскать отрезки, соединяющие углы, и разбить их на пары соответствия, тоже не составит труда. Далее можно сделать предположение, что четыре отрезка, образующих замкнутую ломаную, ограничивают плоскость[Оглянитесь вокруг, и вы увидите, что чаще всего так и бывает]. Вот наша задача и решена! Теперь мы можем построить тот самый куб, составив его из плоскостей. Если наш робот наткнется на кружку или кастрюлю, он без труда распознает в ее основании окружность, что поможет ему «разобраться» и с формой этого предмета. Но иногда жестко закреплять глаза робота нецелесообразно или вообще ненужно, поскольку восстановить положение камер по двум снимкам не слишком трудно. К тому же это решение зачастую дает более высокую точность, нежели механическое соединение камер. Да и возможность независимо оперировать двумя глазами довольно заманчива, особенно в тех задачах, где не требуется восприятие трехмерной информации (например, такой робот сможет одновременно читать две страницы книги).  Так как же восстанавливают положение камер по кадрам? Для этого нам опять потребуются пары соответствующих точек на каждом из изображений (обычно не меньше семи пар). При смене камеры мы просто меняем центр и направление проецирования; таким образом, пара камер характеризуется вектором сдвига (он соединяет оптические центры камер) и поворотом в пространстве одной относительно другой. Если мы посмотрим на две фотографии одного предмета, сделанные с разных точек, то сможем достаточно точно указать искомые параметры пары камер. При этом мы будем руководствоваться изменением взаимного положения точек на фотографиях. Рассуждать мы будем примерно так: «вот этот отрезок стал длиннее, следовательно, теперь он стал более перпендикулярным по отношению к камере, а вот этот короче, а этот повернулся…». Руководствуясь подобными же соображениями, можно построить математическую модель и с ее помощью достаточно точно восстановить параметры пары камер. После того как взаимное положение камер известно, можно для любой точки одного изображения найти прямую на другом, которая будет проходить через точку, соответствующую в пространстве первой. Эта прямая называется эпиполярной и соответствует проекции (e’p’, см. рис. справа внизу) на вторую камеру прямой (OP), соединяющей точку в пространстве (P) с оптическим центром первой камеры (O). Понятно, что конфигурация эпиполярных линий определяется только параметрами пары камер и не зависит от конфигурации 3D-сцены. После того как построены эпиполярные линии, мы можем искать точку, соответствующую данной, не по всему второму изображению, а только вдоль эпиполярной прямой, что не только сильно снижает вычислительную сложность алгоритма, но и позволяет находить такие соответствия, которые другими методами просто были бы пропущены. Вернемся к примеру с кубом. Пусть у нас уже построены эпиполярные линии и найдены соответствия между вершинами и гранями куба. Теперь мы можем для любой точки на грани куба найти соответствие: строим эпиполярную линию, которая пересечет грань куба на втором изображении в единственном месте, оно-то и будет точкой, соответствующей первой.  Вспомним про третий инструмент человеческого восприятия трехмерного пространства — выявление знакомых предметов со знакомыми размерами. Этот метод применим только для довольно узкого класса задач. Например, индустриальный робот только и делает, что перекладывает пять различных типов заготовок с места на место и вполне может их «узнавать», а вот для ориентирования в произвольном помещении такой метод вряд ли подойдет. Знаменитый робот-собака Aibo может находить и узнавать свои игрушки, но для этого они специальным образом раскрашиваются. Можно и с одной камерой составить представление о трехмерном мире, но для этого роботу придется двигаться и, сохраняя предыдущие кадры в памяти, использовать их аналогично кадрам со второй камеры. При таком алгоритме существенно упрощается поиск парных соответствий. Ведь если сохранять кадры часто, то на двух соседних соответствующие точки будут лежать недалеко друг от друга. Более того, если результат покажется недостаточно точным, можно продолжить движение и уточнить его. Теперь рассмотрим возможности, которые недоступны человеку, но вполне могут быть реализованы в роботах. Существенно увеличить точность восстановления 3D можно, используя третий глаз. Именно так и поступила компания Sony, спроектировав робота Qrio. Правда, он использует третий глаз не только для ориентирования в пространстве, но и для увеличения многозадачности. Все описанные методы являются пассивными — робот не генерирует никаких сигналов. Существуют также и активные системы; некоторые из них сродни эхолотам дельфинов и акустическим радарам летучих мышей. Робот посылает направленную акустическую или электромагнитную волну и по отраженной волне, которую сам и принимает, получает информацию о расстоянии до преграды. Такой аппаратурой обычно оснащаются роботы, действующие на открытой местности, где оптические методы не всегда эффективны (выбрать соответствующие друг другу точки очень трудно из-за сложной формы объектов и обилия сильно текстурированных областей). 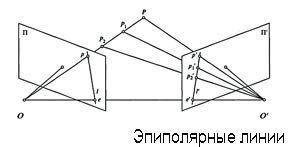 Рассмотрим системы с оптической подсветкой. Если установить на робота одну камеру и лазер, который создает яркое пятнышко на поверхности предметов, то по скорости перемещения пятна можно судить о дистанции до предмета, а по ускорению — о наклоне поверхности (при наличии двух или более камер). Таким образом, можно «прощупать» лазером все поле зрения робота. Но согласитесь, многим не понравится, если механический курьер в офисе будет всюду шарить лазером. Впрочем, можно взять лазер, излучающий в невидимом диапазоне. Еще более изящное решение — использовать структурированную подсветку. Все поле зрения робота засвечивается лазерной решеткой, и расстояние до преграды определяется по шагу решетки на кадре: чем он больше — тем и расстояние больше. Такие системы не смогут работать с зеркальными поверхностями, но согласитесь, что в стеклянном лабиринте не сможет сориентироваться даже человек, поэтому всерьез этот недостаток воспринимать не следует. В существующих системах обычно используются несколько методов. Ведь в условиях, неблагоприятных для одного из них, другой может дать неплохие результаты, а одновременное применение разных методов позволяет сильно уменьшить вероятность ошибки.  Гонку робомобилей DARPA Grand Challenge выиграл колесный кибер Stanley. Автопробег был организован американским Агентством содействия оборонным разработкам (DARPA) и проводился в пустыне Мохаве, штат Невада. Участникам пришлось преодолеть 240-километровую трассу по пересеченной местности. Автомобиль Stanley, созданный специалистами Стэнфордского университета на базе джипа Volkswagen Touareg, был оснащен мощным комплексом цифрового зрения и системой GPS, предназначенной для определения местонахождения. При медленном движении Stanley использовал систему лазерного сканирования, которая позволяла распознавать даже небольшие препятствия в радиусе 25 метров. Но этого не хватало для движения на большой скорости. Более того, лазерный дальномер принимает лужу за идеально ровную поверхность, из-за чего в прошлом году многие участники сошли с трассы: их машины выбрали путь через заполненные водой ямы. Для обнаружения крупных препятствий на значительном удалении и выяснения общего рельефа местности Stanley использует радиолокационную систему, которая способна распознать камень размером с ведро на расстоянии больше двухсот метров. Есть на машине и оптическая система, которая служит для поиска дороги и обнаружения мелких препятствий. Она сделана таким образом, что если какой-то участок дороги вызывает «подозрение», автомобиль снизит скорость и, подъехав поближе, либо «разберется», что же на этом участке происходит, либо объедет его.  Даже такая сложная система зрения позволила победителю ралли развить среднюю скорость лишь немногим больше 30 км/час. Во многом это, конечно, связано со сложностью маршрута, но понятно, что до результатов настоящих раллийных пилотов роботам пока далеко. |
|
|||
|
Главная | Контакты | Прислать материал | Добавить в избранное | Сообщить об ошибке |
||||
|
|
||||